Chapter 11 - Strings with {stringr}
Vebash Naidoo
31/10/2020
Last updated: 2020-11-21
Checks: 7 0
Knit directory: r4ds_book/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200814) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 6e7b3db. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rproj.user/
Untracked files:
Untracked: analysis/images/
Untracked: code_snipp.txt
Untracked: data/at_health_facilities.csv
Untracked: data/infant_hiv.csv
Untracked: data/measurements.csv
Untracked: data/person.csv
Untracked: data/ranking.csv
Untracked: data/visited.csv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/ch11_strings.Rmd) and HTML (docs/ch11_strings.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 7ed0458 | sciencificity | 2020-11-10 | Build site. |
| html | 86457fa | sciencificity | 2020-11-10 | Build site. |
| html | 4879249 | sciencificity | 2020-11-09 | Build site. |
| html | e423967 | sciencificity | 2020-11-08 | Build site. |
| html | 0d223fb | sciencificity | 2020-11-08 | Build site. |
| html | ecd1d8e | sciencificity | 2020-11-07 | Build site. |
| html | 274005c | sciencificity | 2020-11-06 | Build site. |
| html | 60e7ce2 | sciencificity | 2020-11-02 | Build site. |
| Rmd | 967fd8a | sciencificity | 2020-11-02 | finished ch11 |
| html | db5a796 | sciencificity | 2020-11-01 | Build site. |
| Rmd | 2cd3513 | sciencificity | 2020-11-01 | more of ch11 |
| html | d8813e9 | sciencificity | 2020-11-01 | Build site. |
| Rmd | 3ec3460 | sciencificity | 2020-11-01 | more of ch11 |
| html | bf15f3b | sciencificity | 2020-11-01 | Build site. |
| Rmd | a8057e7 | sciencificity | 2020-11-01 | added ch11 |
| html | 0aef1b0 | sciencificity | 2020-10-31 | Build site. |
| Rmd | 72ad7d9 | sciencificity | 2020-10-31 | added ch10 |
Strings
Click on the tab buttons below for each section
String Basics
String Basics
(string1 <- "This is a string")
#> [1] "This is a string"
(string2 <- 'To put a "quote" inside a string, use single quotes')
#> [1] "To put a \"quote\" inside a string, use single quotes"
writeLines(string1)
#> This is a string
writeLines(string2)
#> To put a "quote" inside a string, use single quotesdouble_quote <- "\"" # or '"'
single_quote <- '\'' # or "'"If you want to include a literal backslash, you’ll need to double it up: "\\".
The printed representation of a string is not the same as string itself, because the printed representation shows the escapes. To see the raw contents of the string, use writeLines():
x <- c("\"", "\\")
x
#> [1] "\"" "\\"
writeLines(x)
#> "
#> \Other useful ones:
"\n": newline"\t": tab- See the complete list by getting help on
":?'"', or?"'". - When you see strings like
"\u00b5", this is a way of writing non-English characters.
(string3 <- "This\tis\ta\tstring\twith\t\ttabs\tin\tit.\nHow about that?")
#> [1] "This\tis\ta\tstring\twith\t\ttabs\tin\tit.\nHow about that?"
writeLines(string3)
#> This is a string with tabs in it.
#> How about that?
## From `?'"'` help page
## Backslashes need doubling, or they have a special meaning.
x <- "In ALGOL, you could do logical AND with /\\."
print(x) # shows it as above ("input-like")
#> [1] "In ALGOL, you could do logical AND with /\\."
writeLines(x) # shows it as you like it ;-)
#> In ALGOL, you could do logical AND with /\.Some String Functions
Some String Functions
String Length
Use str_length().
str_length(c("a", "R for Data Science", NA))
#> [1] 1 18 NACombining Strings
Use str_c().
- Use
sep = some_charto separate values with a character, the default separator is the empty string. - Shorter length vectors are recycled.
- Use
str_replace_na(list)to replace NAs with literal NA. - Objects of length 0 are silently dropped.
- Use `collapse to reduce a vector of strings to a single string.
str_c("a", "R for Data Science")
#> [1] "aR for Data Science"
str_c("x", "y", "z")
#> [1] "xyz"
str_c("x", "y", "z", sep = ", ") # separate using character
#> [1] "x, y, z"
str_c("prefix-", c("a","b", "c"), "-suffix")
#> [1] "prefix-a-suffix" "prefix-b-suffix" "prefix-c-suffix"x <- c("abc", NA)
str_c("|=", x, "=|") # concatenating a 1 long, with 2 long, with 1 long
#> [1] "|=abc=|" NA
str_c("|=", str_replace_na(x), "=|") # to actually show the NA
#> [1] "|=abc=|" "|=NA=|"Notice that the shorter vector is recycled.
Objects of 0 length are dropped.
name <- "Vebash"
time_of_day <- "evening"
birthday <- FALSE
str_c("Good ", time_of_day, " ",
name, if(birthday) ' and Happy Birthday!')
#> [1] "Good evening Vebash"
str_c("prefix-", c("a","b", "c"), "-suffix", collapse = ', ')
#> [1] "prefix-a-suffix, prefix-b-suffix, prefix-c-suffix"
str_c("prefix-", c("a","b", "c"), "-suffix") # note the diff without
#> [1] "prefix-a-suffix" "prefix-b-suffix" "prefix-c-suffix"Subsetting Strings
Use str_sub().
startandendargs give the (inclusive) position of the substring you’re looking for.- does not fail if string too short, returns as much as it can.
- can use the assignment operator of
str_sub()to modify strings.
x <- c("Apple", "Banana", "Pear")
str_sub(x, 1, 3) # get 1st three chars of each
#> [1] "App" "Ban" "Pea"
str_sub(x, -3, -1) # get last three chars of each
#> [1] "ple" "ana" "ear"
str_sub("a", 1, 5) # too short but no failure
#> [1] "a"
x # before change
#> [1] "Apple" "Banana" "Pear"
# Go get from x the 1st char, and assign to it
# the lower version of its character
str_sub(x, 1, 1) <- str_to_lower(str_sub(x, 1, 1))
x # after the str_sub assign above
#> [1] "apple" "banana" "pear"Locales
str_to_lower(), str_to_upper() and str_to_title() are all functions that amend case. Amending case may be dependant on your locale though.
# Turkish has two i's: with and without a dot, and it
# has a different rule for capitalising them:
str_to_upper(c("i", "ı"))
#> [1] "I" "I"
str_to_upper(c("i", "ı"), locale = "tr")
#> [1] "I" "I"Sorting is also affected by locales. In Base R we use sort or order, in {stringr} we use str_sort() and str_order() with the additional argument locale.
x <- c("apple", "banana", "eggplant")
str_sort(x, locale = "en")
#> [1] "apple" "banana" "eggplant"
str_sort(x, locale = "haw")
#> [1] "apple" "eggplant" "banana"
str_order(x, locale = "en")
#> [1] 1 2 3
str_order(x, locale = "haw")
#> [1] 1 3 2Exercises
In code that doesn’t use stringr, you’ll often see
paste()andpaste0(). What’s the difference between the two functions? What stringr function are they equivalent to? How do the functions differ in their handling ofNA?# from the help page ## When passing a single vector, paste0 and paste work like as.character. paste0(1:12) #> [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" paste(1:12) # same #> [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" as.character(1:12) # same #> [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" ## If you pass several vectors to paste0, they are concatenated in a ## vectorized way. (nth <- paste0(1:12, c("st", "nd", "rd", rep("th", 9)))) #> [1] "1st" "2nd" "3rd" "4th" "5th" "6th" "7th" "8th" "9th" "10th" #> [11] "11th" "12th" (nth <- paste(1:12, c("st", "nd", "rd", rep("th", 9)))) #> [1] "1 st" "2 nd" "3 rd" "4 th" "5 th" "6 th" "7 th" "8 th" "9 th" #> [10] "10 th" "11 th" "12 th" (nth <- str_c(1:12, c("st", "nd", "rd", rep("th", 9)))) #> [1] "1st" "2nd" "3rd" "4th" "5th" "6th" "7th" "8th" "9th" "10th" #> [11] "11th" "12th" (na_th <- paste0(1:13, c("st", "nd", "rd", rep("th", 9), NA))) #> [1] "1st" "2nd" "3rd" "4th" "5th" "6th" "7th" "8th" "9th" "10th" #> [11] "11th" "12th" "13NA" (na_th <- paste(1:13, c("st", "nd", "rd", rep("th", 9), NA))) #> [1] "1 st" "2 nd" "3 rd" "4 th" "5 th" "6 th" "7 th" "8 th" "9 th" #> [10] "10 th" "11 th" "12 th" "13 NA" (na_th <- str_c(1:13, c("st", "nd", "rd", rep("th", 9), NA))) #> [1] "1st" "2nd" "3rd" "4th" "5th" "6th" "7th" "8th" "9th" "10th" #> [11] "11th" "12th" NApaste()inserts a space between values, and may be overridden withsep = "". In other words the default separator is a space.paste0()has a separator that is by default the empty string so resulting vector values have no spaces in between.str_c()is the stringr equivalent.paste()andpaste0()treat NA values as literal string NA, whereasstr_ctreats NA as missing and that vectorised operation results in an NA.
In your own words, describe the difference between the
sepandcollapsearguments tostr_c().sepis the separator that appears between vector values when these are concatenated in a vectorised fashion.collapseis the separator between values when all vectors are collapsed into a single contiguous string value.
(na_th_sep <- str_c(1:12, c("st", "nd", "rd", rep("th", 9)), # sep only sep = "'")) #> [1] "1'st" "2'nd" "3'rd" "4'th" "5'th" "6'th" "7'th" "8'th" "9'th" #> [10] "10'th" "11'th" "12'th" (na_th_col <- str_c(1:12, c("st", "nd", "rd", rep("th", 9)), # collapse only collapse = "; ")) #> [1] "1st; 2nd; 3rd; 4th; 5th; 6th; 7th; 8th; 9th; 10th; 11th; 12th" (na_th <- str_c(1:12, c("st", "nd", "rd", rep("th", 9)), # both sep = " ", collapse = ", ")) #> [1] "1 st, 2 nd, 3 rd, 4 th, 5 th, 6 th, 7 th, 8 th, 9 th, 10 th, 11 th, 12 th"Use
str_length()andstr_sub()to extract the middle character from a string. What will you do if the string has an even number of characters?x <- "This is a string." y <- "This is a string, no full stop" z <- "I" str_length(x)/2 #> [1] 8.5 str_length(y)/2 #> [1] 15 str_sub(x, ceiling(str_length(x)/2), ceiling(str_length(x)/2)) #> [1] "a" str_sub(y, str_length(y)/2, str_length(y)/2 + 1) #> [1] "ng" str_sub(z, ceiling(str_length(z)/2), ceiling(str_length(z)/2)) #> [1] "I"What does
str_wrap()do? When might you want to use it?It is a wrapper around stringi::stri_wrap() which implements the Knuth-Plass paragraph wrapping algorithm.
The text is wrapped based on a given width. The default is 80, overridding this to 40 will mean 40 characters on a line. Further arguments such as
indent(the indentation of start of each paragraph) may be specified.What does
str_trim()do? What’s the opposite ofstr_trim()?It removes whitespace from the left and right of a string.
str_pad()is the opposite functionality.str_squish()removes extra whitepace, in beginning of string, end of string and the middle. 🥂(x <- str_trim(" This has \n some spaces in the middle and end ")) #> [1] "This has \n some spaces in the middle and end" # whitespace removed from begin and end of string writeLines(x) #> This has #> some spaces in the middle and end (y <- str_squish(" This has \n some spaces in the middle and end ... oh, not any more ;)")) #> [1] "This has some spaces in the middle and end ... oh, not any more ;)" # whitespace removed from begin, middle and end of string writeLines(y) #> This has some spaces in the middle and end ... oh, not any more ;)Write a function that turns (e.g.) a vector
c("a", "b", "c")into the stringa, b, and c. Think carefully about what it should do if given a vector of length 0, 1, or 2.- length 0: return empty string
- length 1: return string
- length 2: return first part “and” second part
- length 3: return first part “,” second part “and” third part.
stringify <- function(v){ if (length(v) == 0 | length(v) == 1){ v } else if (length(v) == 2){ str_c(v, collapse = " and ") } else if (length(v) > 2){ str_c(c(rep("", (length(v) - 1)), " and "), v, c(rep(", ", (length(v) - 2)), rep("", 2)), collapse = "") } } emp <- "" stringify(emp) #> [1] "" x <- "a" stringify(x) #> [1] "a" y <- c("a", "b") stringify(y) #> [1] "a and b" z <- c("a", "b", "c") stringify(z) #> [1] "a, b and c" l <- letters stringify(letters) #> [1] "a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y and z"
Pattern Matching with Regex
Pattern Matching with Regex
Find a specific pattern
x <- c("apple", "banana", "pear")
# find any "an" char seq in vector x
str_view(x, "an")Find any character besides the newline char.
# find any char followed by an "a" followed by any char str_view(x, ".a.")What if we want to literally match
.?We need to escape the
.to say “hey, literally find me a . char in the string, I don’t want to use it’s special behaviour this time”.\\.(dot <- "\\.") #> [1] "\\." writeLines(dot) #> \. str_view(c("abc", "a$c", "a.c", "b.e"), # find a char # followed by a literal . # followed by another char ".\\..")What if we want the literal
\?Recall that to add a literal backslash in a string we have to escape it using
\\.(backslash <- "This string contains the \\ char and we want to find it.") #> [1] "This string contains the \\ char and we\nwant to find it." writeLines(backslash) #> This string contains the \ char and we #> want to find it.So to find it using regex we need to escape each backslash in our regex i.e.
\\\\. 👿writeLines(backslash) #> This string contains the \ char and we #> want to find it. str_view(backslash, "\\\\")
Exercises
Explain why each of these strings don’t match a
\:"\","\\","\\\".As we saw above in a string to literally print a
\we use"\\". If we need to match it we need to escape each\, with a\. Since we have two\’s in a string, matching requires 2 * 2 i.e. 4\How would you match the sequence
"'\?(string4 <- "This is the funky string: \"\'\\") #> [1] "This is the funky string: \"'\\" writeLines(string4) #> This is the funky string: "'\ str_view(string4, "\\\"\\\'\\\\")What patterns will the regular expression
\..\..\..match? How would you represent it as a string?It matches the pattern literal . followed by any character x 3.
(string5 <- ".x.y.z something else .z.a.r") #> [1] ".x.y.z something else .z.a.r" writeLines(string5) #> .x.y.z something else .z.a.r str_view_all(string5, "\\..\\..\\..")
Anchors
Anchors
Use:
^to match the start of the string.$to match the end of the string.x #> [1] "apple" "banana" "pear" str_view(x, "^a") # any starting with a?str_view(x, "a$") # any ending with a?To match a full string (not just the string being a part of a bigger string).
(x <- c("apple pie", "apple", "apple cake")) #> [1] "apple pie" "apple" "apple cake" str_view(x, "apple") # match any "apple"str_view(x, "^apple$") # match the word "apple"Match boundary between words with
\b.
Exercises
How would you match the literal string
"$^$"?(x <- "How would you match the literal string $^$?") #> [1] "How would you match the literal string $^$?" str_view(x, "\\$\\^\\$")Given the corpus of common words in
stringr::words, create regular expressions that find all words that:- Start with “y”.
stringr::words %>% as_tibble() #> # A tibble: 980 x 1 #> value #> <chr> #> 1 a #> 2 able #> 3 about #> 4 absolute #> 5 accept #> 6 account #> 7 achieve #> 8 across #> 9 act #> 10 active #> # ... with 970 more rows str_view(stringr::words, "^y", match = TRUE)- End with “x”
str_view(stringr::words, "x$", match = TRUE)- Are exactly three letters long. (Don’t cheat by using
str_length()!)
str_view(stringr::words, "^...$", match = TRUE)- Have seven letters or more.
str_view(stringr::words, "^.......", match = TRUE)Since this list is long, you might want to use the
matchargument tostr_view()to show only the matching or non-matching words.
Character classes
Character classes
\d: matches any digit.\s: matches any whitespace (e.g. space, tab, newline).[abc]: matches a, b, or c.[^abc]: matches anything except a, b, or c.
To create a regular expression containing \d or \s, we’ll need to escape the \ for the string, so we’ll type "\\d" or "\\s".
A character class containing a single character is a nice alternative to backslash escapes when we’re looking for a single metacharacter in a regex.
(x <- "How would you match the literal string $^$?")
#> [1] "How would you match the literal string $^$?"
str_view(x, "[$][\\^][$]")
(y <- "This sentence has a full stop. Can we find it?")
#> [1] "This sentence has a full stop. Can we find it?"
str_view(y, "[.]")
# Look for a literal character that normally has special meaning in a regex
str_view(c("abc", "a.c", "a*c", "a c"), "a[.]c")str_view(c("abc", "a.c", "a*c", "a c"), ".[*]c")str_view(c("abc", "a.c", "a*c", "a c"), "a[ ]")This works for most (but not all) regex metacharacters:
- Works for:
$.|?*+()[{. - Does not work for: Some characters have special meaning even inside a character class, and hence must be handled with backslash escapes. These are
]\^and-. E.g. In the first example above.
You can use alternation to pick between one or more alternative patterns. For example, abc|d..f will match either ‘“abc”’, or "deaf". Note that the precedence for | is low, and hence may be confusing (e.g. we may have expected the above to match either abc or abdeaf or abchgf, but it does not - it matches either the first part abc OR the second part dxxf). We need to use parentheses to make it clear what we are looking for.
str_view(c("grey", "gray"), "gr(e|a)y")Exercises
Create regular expressions to find all words that:
Start with a vowel.
reg_ex <- "^[aeiou]" (x <- c("aardvark", "bat", "umbrella", "escape", "xray", "owl")) #> [1] "aardvark" "bat" "umbrella" "escape" "xray" "owl" str_view(x, reg_ex)That only contain consonants. (Hint: thinking about matching “not”-vowels.)
I don’t know how to do this with only the tools we have learnt so far so you will see a new character below
+that is after the character class end bracket - this means one or more, i.e. find words that contain one or more non-vowel words instringr::words.reg_ex <- "^[^aeiou]+$" str_view(stringr::words, reg_ex, match = TRUE)End with
ed, but not witheed.reg_ex <- "[^e][e][d]$" str_view(stringr::words, reg_ex, match = TRUE)End with
ingorise.reg_ex <- "i(ng|se)$" str_view(stringr::words, reg_ex, match = TRUE)
Empirically verify the rule “i before e except after c”.
correct_reg_ex <- "[^c]ie|[c]ei" str_view(stringr::words, correct_reg_ex, match = TRUE)opp_reg_ex <- "[^c]ei|[c]ie" # opp is e before i before a non c str_view(stringr::words, opp_reg_ex, match = TRUE)Is “q” always followed by a “u”?
reg_ex <- "q[^u]" str_view(stringr::words, reg_ex, match = TRUE)reg_ex <- "qu" str_view(stringr::words, reg_ex, match = TRUE)In the
stringr::wordsdataset yes.Write a regular expression that matches a word if it’s probably written in British English, not American English.
reg_ex <- "col(o|ou)r" str_view(c("colour", "color", "colouring"), reg_ex)reg_ex <- "visuali(s|z)(e|ation)" str_view(c("visualisation", "visualization", "visualise", "visualize"), reg_ex)Create a regular expression that will match telephone numbers as commonly written in your country.
reg_ex <- "[+]27[(]0[)][\\d]+" str_view(c("0828907654", "+27(0)862345678", "777-8923-111"), reg_ex)
Repetition
Repetition
The next step up in power involves controlling how many times a pattern matches:
?: 0 or 1+: 1 or more*: 0 or more
You can also specify the number of matches precisely:
{n}: exactly n{n,}: n or more{,m}: at most m{n,m}: between n and m
x <- "1888 is the longest year in Roman numerals: MDCCCLXXXVIII"
str_view(x, "CC?") # C or CC if exists
str_view(x, "CC+") # CC or CCC or CCCC etc. at least two C's
# CL or CX or CLX at least 1 C, followed by one of more L's & X's
str_view(x, "C[LX]+")
str_view(x, "C{2}") # find exactly 2 C's
str_view(x, "C{1,}") # find 1 or more C's
str_view(x, "C{1,2}") # min 1 C, max 2 C's
(y <- '<span style="color:#008080;background-color:#9FDDBA">`alpha`<//span>')
#> [1] "<span style=\"color:#008080;background-color:#9FDDBA\">`alpha`<//span>"
writeLines(y)
#> <span style="color:#008080;background-color:#9FDDBA">`alpha`<//span>
# .*? - find to the first > otherwise greedy
str_view(y, '^<.*?(>){1,}') The ? after .* makes the matching less greedy. It finds the first multiple characters until a > is encountered
Exercises
Describe the equivalents of
?,+,*in{m,n}form.?- {0,1} 0 or 1+- {1,} 1 or more*- {0,} 0 or more
Describe in words what these regular expressions match: (read carefully to see if I’m using a regular expression or a string that defines a regular expression.)
^.*$Matches any string that does not contain a newline character in it. String defining regular expression.reg_ex <- "^.*$" (x <- "This is a string with 0 newline chars") #> [1] "This is a string with 0 newline chars" writeLines(x) #> This is a string with 0 newline chars str_view(x, reg_ex)(y <- "This is a string with a couple \n\n newline chars") #> [1] "This is a string with a couple \n\n newline chars" writeLines(y) #> This is a string with a couple #> #> newline chars str_view(y, reg_ex)Notice no match for y (none of the text highlighted).
"\\{.+\\}"Matches a
{followed by one or more of any character but the newline character followed by the}. String defining a regular expression.reg_ex <- "\\{.+\\}" str_view(c("{a}", "{}", "{a,b,c}", "{a, b\n, c}"), reg_ex)Notice that
{a, b , c}is not highlighted, this is because there is a\n(newline sequence) after the b.\d{4}-\d{2}-\d{2}Matches exactly 4 digits followed by a - followed by exactly 2 digits, followed by a -, followed by exactly 2 digits. Regular expression (the
\dneeds another ).reg_ex <- "\\d{4}-\\d{2}-\\d{2}" str_view(c("1234-34-12", "12345-34-23", "084-87-98", "2020-01-01"), reg_ex)"\\\\{4}"Matches exactly 4 backslashes. String defining reg expr.
reg_ex <- "\\\\{4}" str_view(c("\\\\", "\\\\\\\\"), reg_ex)
Create regular expressions to find all words that:
- Start with three consonants.
reg_ex <- "^[^aeiou]{3}.*" str_view(c("fry", "fly", "scrape", "scream", "ate", "women", "strap", "splendid", "test"), reg_ex)- Have three or more vowels in a row.
reg_ex <- ".*[aeiou]{3,}.*" str_view(stringr::words, reg_ex, match=TRUE)- Have two or more vowel-consonant pairs in a row.
reg_ex <- ".*([aeiou][^aeiou]){2,}.*" str_view(stringr::words, reg_ex, match = TRUE)Solve the beginner regexp crosswords at https://regexcrossword.com/challenges/beginner.
Backreferences
Backreferences
Parentheses can be used to make complex expressions more clear, and can also create a numbered capturing group (number 1, 2 etc.). A capturing group stores the part of the string matched by the part of the regular expression inside the parentheses. You can refer to the same text as previously matched by a capturing group with backreferences, like \1, \2 etc.
The following regex finds all fruits that have a repeated pair of letters.
# (..)\\1 says find any two letters - these are a group, is
# this then followed by the same 2 letters?
# Yes - match found
# No - whawha
str_view(fruit, "(..)\\1", match = TRUE)For e.g. for banana:
- It starts at “ba” that becomes the group 1, then it moves it along and says is the next 2 letters “ba” (i.e. equivalent to group 1) too? Nope.
- It moves along to “an” and that is the new group 1. Then it moves along and says - are the next two letters equivalent to group 1 (i.e. is it “an”) - Yes it is! found a word that matches.
Exercises
Describe, in words, what these expressions will match:
(.)\1\1This matches any character repeated three times.
reg_ex <- "(.)\\1\\1" str_view(c("Oooh", "Ahhh", "Awww", "Ergh"), reg_ex)Note that
Oandoare different."(.)(.)\\2\\1"This matches any two characters repeated once in reverse order. e.g. abba
reg_ex <- "(.)(.)\\2\\1" str_view(c("abba"), reg_ex)str_view(words, reg_ex, match=TRUE)(..)\1This matches two letters that appear twice. b
anana.str_view(fruit, "(..)\\1", match = TRUE)"(.).\\1.\\1"This matches a character followed by another char followed by the same character as the start, followed by another char, followed by the character. e.g. abaca
str_view(words, "(.).\\1.\\1", match = TRUE)"(.)(.)(.).*\\3\\2\\1"This matches three characters followed by 0 or more other characters, ending with the 3 characters at the start in reverse order.
reg_ex <- "(.)(.)(.).*\\3\\2\\1" str_view(c("bbccbb"), reg_ex)str_view(words, reg_ex, match=TRUE)
Construct regular expressions to match words that:
- Start and end with the same character.
reg_ex <- "^(.).*\\1$" str_view(words, reg_ex, match = TRUE)- Contain a repeated pair of letters (e.g. “church” contains “ch” repeated twice.)
reg_ex <- "(..).*\\1" str_view("church", reg_ex)str_view(words, reg_ex, match=TRUE)- Contain one letter repeated in at least three places (e.g. “eleven” contains three “e”s.)
reg_ex <- "(.).*\\1.*\\1" str_view(words, reg_ex, match = TRUE)
Detect Matches
Detect Matches
str_detect()
Use str_detect(). It returns a logical vector the same length as the input.
Since it is a logical vector and numerically TRUE == 1 and FALSE == 0 we can also use sum(), mean() to get information about matches found.
(x <- c("apple", "banana", "pear"))
#> [1] "apple" "banana" "pear"
str_detect(x, "e")
#> [1] TRUE FALSE TRUEx
#> [1] "apple" "banana" "pear"
sum(str_detect(x, "e"))
#> [1] 2
# How many common words start with t?
sum(str_detect(words, "^t"))
#> [1] 65
# What proportion of common words end with a vowel?
mean(str_detect(words, "[aeiou]$"))
#> [1] 0.2765306# Find all words containing at least one vowel, and negate
no_vowels_1 <- !str_detect(words, "[aeiou]")
# Find all words consisting only of consonants (non-vowels)
no_vowels_2 <- str_detect(words, "^[^aeiou]+$")
identical(no_vowels_1, no_vowels_2)
#> [1] TRUE
# you can also use `negate = TRUE`
no_vowels_3 <- str_detect(words, "[aeiou]", negate = TRUE)
identical(no_vowels_1, no_vowels_3)
#> [1] TRUE
identical(no_vowels_3, no_vowels_2)
#> [1] TRUEstr_subset()
We use str_detect() often to match patterns using the wrapper str_subset().
words[str_detect(words, "x$")]
#> [1] "box" "sex" "six" "tax"
# str_subset() is a wrapper around x[str_detect(x, pattern)]
str_subset(words, "x$")
#> [1] "box" "sex" "six" "tax"filter(str_detect())
When we want to find matches in a column in a dataframe we can combine str_detect() with filter().
(df <- tibble(
word = words,
i = seq_along(word)
))
#> # A tibble: 980 x 2
#> word i
#>
#> 1 a 1
#> 2 able 2
#> 3 about 3
#> 4 absolute 4
#> 5 accept 5
#> 6 account 6
#> 7 achieve 7
#> 8 across 8
#> 9 act 9
#> 10 active 10
#> # ... with 970 more rows
df %>%
filter(str_detect(word, "x$"))
#> # A tibble: 4 x 2
#> word i
#>
#> 1 box 108
#> 2 sex 747
#> 3 six 772
#> 4 tax 841 str_count()
Instead of using str_detect() which returns a TRUE OR FALSE we can use str_count() which gives us a number of matches in each string.
(x <- c("apple", "banana", "pear"))
#> [1] "apple" "banana" "pear"
str_count(x, "e")
#> [1] 1 0 1
str_count(x, "a")
#> [1] 1 3 1
# On average, how many vowels per word?
mean(str_count(words, "[aeiou]"))
#> [1] 1.991837We often use str_count() with mutate().
df %>%
mutate(vowels = str_count(word, "[aeiou]"),
consonants = str_count(word, "[^aeiou]"))
#> # A tibble: 980 x 4
#> word i vowels consonants
#> <chr> <int> <int> <int>
#> 1 a 1 1 0
#> 2 able 2 2 2
#> 3 about 3 3 2
#> 4 absolute 4 4 4
#> 5 accept 5 2 4
#> 6 account 6 3 4
#> 7 achieve 7 4 3
#> 8 across 8 2 4
#> 9 act 9 1 2
#> 10 active 10 3 3
#> # ... with 970 more rowsMatches never overlap. For example, in "abababa", the pattern "aba" matches twice. You can think of it as placing a marker at the beginning of the string, then moving along looking for pattern, it sees a then b then a, so it has found one pattern == aba. The marker is lying at the 4th letter in the string. It proceeds from there to look for more occurrences of the pattern. b does not do it, so it skips over and goes to the 5th character a, then the 6th b, then the 7th a and has found another occurrence. Hence 2 occurrences found. I.e it moves sequentially over the string, and does not brute force every combination in the string.
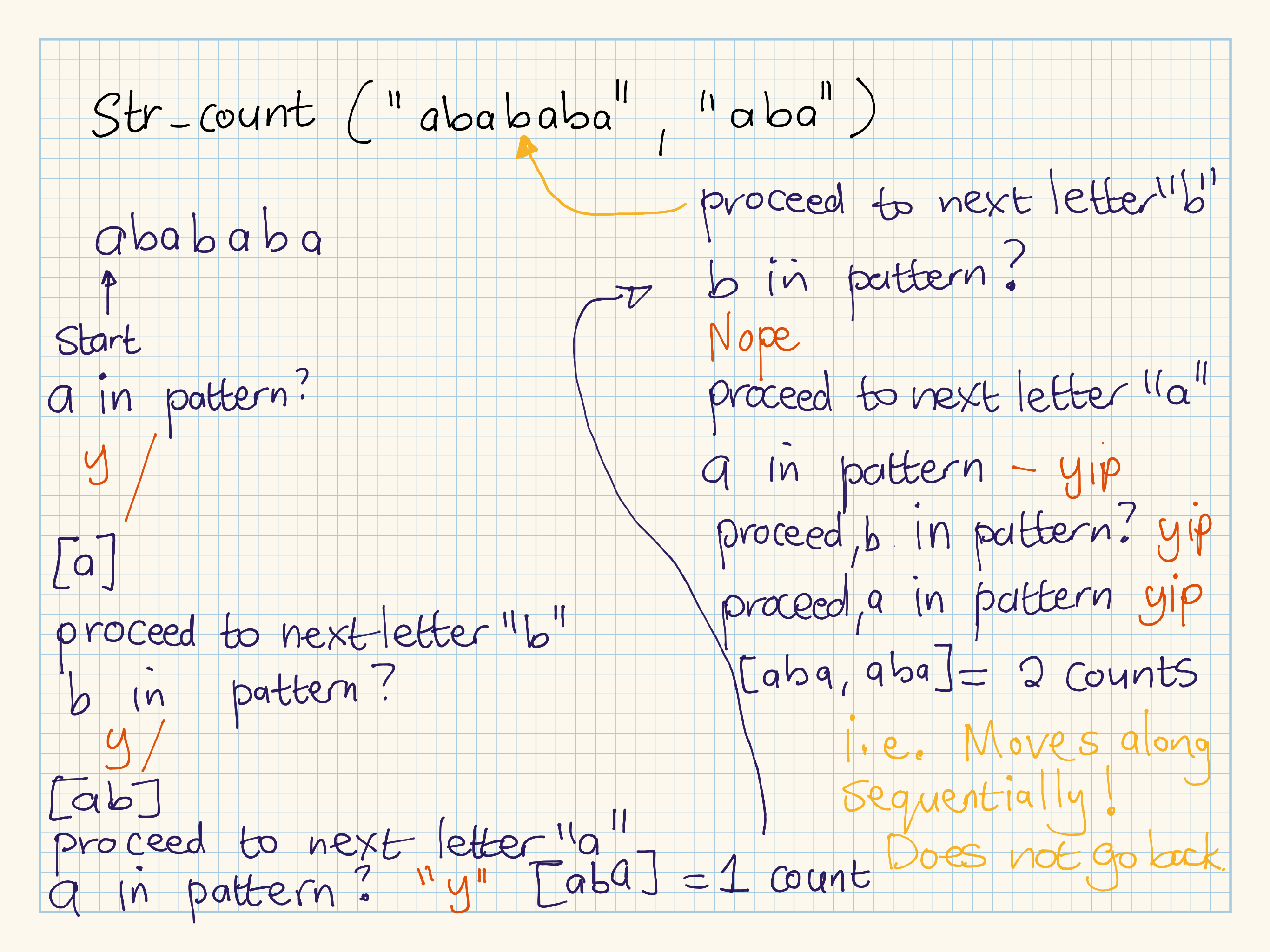
str_count("abababa", "aba")
#> [1] 2
str_view_all("abababa", "aba")Exercises
For each of the following challenges, try solving it by using both a single regular expression, and a combination of multiple
str_detect()calls.Find all words that start or end with
x.reg_ex <- "(^x.*|.*x$)" str_view(words, reg_ex, match = TRUE)str_detect(c("xray", "box", "text", "vex"), reg_ex) #> [1] TRUE TRUE FALSE TRUE reg_ex <- "(^x.*|.*x$)" str_detect(c("xray", "box", "text", "vex"), "^x") | str_detect(c("xray", "box", "text", "vex"), "x$") #> [1] TRUE TRUE FALSE TRUEFind all words that start with a vowel and end with a consonant.
reg_ex <- "^[aeiou].*[^aeiou]$" df %>% filter(str_detect(word, reg_ex)) #> # A tibble: 122 x 2 #> word i #> <chr> <int> #> 1 about 3 #> 2 accept 5 #> 3 account 6 #> 4 across 8 #> 5 act 9 #> 6 actual 11 #> 7 add 12 #> 8 address 13 #> 9 admit 14 #> 10 affect 16 #> # ... with 112 more rowsAre there any words that contain at least one of each different vowel?
# https://stackoverflow.com/questions/54267095/what-is-the-regex-to-match-the-words-containing-all-the-vowels reg_ex <- "\\b(?=\\w*?a)(?=\\w*?e)(?=\\w*?i)(?=\\w*?o)(?=\\w*?u)[a-zA-Z]+\\b" str_detect(c("eunomia", "eutopia", "sequoia"), reg_ex) #> [1] TRUE TRUE TRUE str_view(c("eunomia", "eutopia", "sequoia"), reg_ex)What word has the highest number of vowels? What word has the highest proportion of vowels? (Hint: what is the denominator?)
df %>% mutate(vowels = str_count(word, "[aeiou]+"), len_word = str_length(word), prop_vowels = vowels / len_word) %>% arrange(-prop_vowels) #> # A tibble: 980 x 5 #> word i vowels len_word prop_vowels #> <chr> <int> <int> <int> <dbl> #> 1 a 1 1 1 1 #> 2 age 22 2 3 0.667 #> 3 ago 24 2 3 0.667 #> 4 eye 296 2 3 0.667 #> 5 one 577 2 3 0.667 #> 6 use 912 2 3 0.667 #> 7 aware 63 3 5 0.6 #> 8 unite 906 3 5 0.6 #> 9 america 36 4 7 0.571 #> 10 educate 258 4 7 0.571 #> # ... with 970 more rows df %>% mutate(vowels = str_count(word, "[aeiou]+"), len_word = str_length(word), prop_vowels = vowels / len_word) %>% arrange(-vowels, -prop_vowels) #> # A tibble: 980 x 5 #> word i vowels len_word prop_vowels #> <chr> <int> <int> <int> <dbl> #> 1 america 36 4 7 0.571 #> 2 educate 258 4 7 0.571 #> 3 imagine 415 4 7 0.571 #> 4 operate 580 4 7 0.571 #> 5 absolute 4 4 8 0.5 #> 6 definite 220 4 8 0.5 #> 7 evidence 283 4 8 0.5 #> 8 exercise 288 4 8 0.5 #> 9 organize 585 4 8 0.5 #> 10 original 586 4 8 0.5 #> # ... with 970 more rowsI see these are two different things. The highest number of vowels, is just the word with the most vowels. The proportion on the other hand is
num_vowels_in_word / num_letters_in_word.
Extract Matches
Extract Matches
To extract the actual text of a match, use str_extract().
length(sentences)
#> [1] 720
head(sentences)
#> [1] "The birch canoe slid on the smooth planks."
#> [2] "Glue the sheet to the dark blue background."
#> [3] "It's easy to tell the depth of a well."
#> [4] "These days a chicken leg is a rare dish."
#> [5] "Rice is often served in round bowls."
#> [6] "The juice of lemons makes fine punch."Let’s say we want to find all sentences that contain a colour.
colours <- c("red", "orange", "yellow", "green", "blue", "purple")
# make a match string by saying red|orange|...|purple
(colour_match <- str_c(colours, collapse = "|"))
#> [1] "red|orange|yellow|green|blue|purple"has_colour <- str_subset(sentences, colour_match)
matches <- str_extract(has_colour, colour_match)
head(matches)
#> [1] "blue" "blue" "red" "red" "red" "blue"more <- sentences[str_count(sentences, colour_match) > 1]
str_view_all(more, colour_match)- To extract multiple matches, use
str_extract_all(). - This returns a list.
- To get this in matrix format use
simplify = TRUE
str_extract_all(more, colour_match)
#> [[1]]
#> [1] "blue" "red"
#>
#> [[2]]
#> [1] "green" "red"
#>
#> [[3]]
#> [1] "orange" "red"
str_extract_all(more, colour_match, simplify = TRUE)
#> [,1] [,2]
#> [1,] "blue" "red"
#> [2,] "green" "red"
#> [3,] "orange" "red"x <- c("a", "a b", "a b c")
str_extract(x, "[a-z]")
#> [1] "a" "a" "a"
str_extract_all(x, "[a-z]", simplify = TRUE)
#> [,1] [,2] [,3]
#> [1,] "a" "" ""
#> [2,] "a" "b" ""
#> [3,] "a" "b" "c"Exercises
In the previous example, you might have noticed that the regular expression matched “flickered”, which is not a colour. Modify the regex to fix the problem.
colours <- c("red", "orange", "yellow", "green", "blue", "purple") # make a match string by saying red|orange|...|purple (colour_match <- str_c(prefix = "\\b", colours, suffix = "\\b", collapse = "|")) #> [1] "\\bred\\b|\\borange\\b|\\byellow\\b|\\bgreen\\b|\\bblue\\b|\\bpurple\\b" more <- sentences[str_count(sentences, colour_match) > 1] str_view_all(more, colour_match)From the Harvard sentences data, extract:
The first word from each sentence.
reg_ex <- "^[A-Za-z']+\\b" first_word <- str_extract(sentences, reg_ex) head(first_word) #> [1] "The" "Glue" "It's" "These" "Rice" "The"All words ending in
ing.reg_ex <- "\\b[a-zA-Z']+ing\\b" words_ <- str_extract_all(str_subset(sentences, reg_ex), reg_ex, simplify = TRUE) head(words_) #> [,1] #> [1,] "spring" #> [2,] "evening" #> [3,] "morning" #> [4,] "winding" #> [5,] "living" #> [6,] "king"All plurals.
Ok so some words end with
sbut are NOT plurals! For e.g.bass,massetc.reg_ex <- "\\b[a-zA-Z]{4,}(es|ies|s)\\b" words_ <- str_extract_all(sentences, reg_ex, simplify = TRUE) head(words_, 10) #> [,1] [,2] [,3] #> [1,] "planks" "" "" #> [2,] "" "" "" #> [3,] "" "" "" #> [4,] "" "" "" #> [5,] "bowls" "" "" #> [6,] "lemons" "makes" "" #> [7,] "" "" "" #> [8,] "" "" "" #> [9,] "hours" "" "" #> [10,] "stockings" "" ""
Grouped Matches
Grouped Matches
So far we have seen parentheses used for:
- disambiguating complex parts of a match
"col(o|ou)r" - creating groups that can be used as backreferences
"(..)\\1" - Another use is to extract parts of complex matches
As an example let’s say we want to get nouns from the sentences dataset.
We can look for a / the
noun <- "(a|the) [^ ]+" # a / the followed by some word (not a space)
(has_noun <- sentences %>%
str_subset(noun) %>%
head(10))
#> [1] "The birch canoe slid on the smooth planks."
#> [2] "Glue the sheet to the dark blue background."
#> [3] "It's easy to tell the depth of a well."
#> [4] "These days a chicken leg is a rare dish."
#> [5] "The box was thrown beside the parked truck."
#> [6] "The boy was there when the sun rose."
#> [7] "The source of the huge river is the clear spring."
#> [8] "Kick the ball straight and follow through."
#> [9] "Help the woman get back to her feet."
#> [10] "A pot of tea helps to pass the evening."
has_noun %>%
# str_extract gives us entire match and each group in a matrix col
str_extract(noun)
#> [1] "the smooth" "the sheet" "the depth" "a chicken" "the parked"
#> [6] "the sun" "the huge" "the ball" "the woman" "a helps"
# in tidyr we can do this for df's using tidyr::extract()
tibble(sentence = sentences) %>%
tidyr::extract(sentence,# from where? sentence
# rename the resulting cols article, and noun
c("article", "noun"),
# pattern with groups for article then noun
"(a|the) ([^ ]+)",
remove = FALSE # keep original sentence col
)
#> # A tibble: 720 x 3
#> sentence article noun
#> <chr> <chr> <chr>
#> 1 The birch canoe slid on the smooth planks. the smooth
#> 2 Glue the sheet to the dark blue background. the sheet
#> 3 It's easy to tell the depth of a well. the depth
#> 4 These days a chicken leg is a rare dish. a chicken
#> 5 Rice is often served in round bowls. <NA> <NA>
#> 6 The juice of lemons makes fine punch. <NA> <NA>
#> 7 The box was thrown beside the parked truck. the parked
#> 8 The hogs were fed chopped corn and garbage. <NA> <NA>
#> 9 Four hours of steady work faced us. <NA> <NA>
#> 10 Large size in stockings is hard to sell. <NA> <NA>
#> # ... with 710 more rowsLike str_extract(), str_match() also has an all equivalent str_match_all().
Exercises
Find all words that come after a “number” like “one”, “two”, “three” etc. Pull out both the number and the word.
(pattern <- str_c(prefix = "\\b", c("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten", "eleven", "twelve"), collapse = "|")) #> [1] "\\bone|\\btwo|\\bthree|\\bfour|\\bfive|\\bsix|\\bseven|\\beight|\\bnine|\\bten|\\beleven|\\btwelve" pattern <- glue::glue("({pattern}) ([^ ]+)") tibble(sentence = sentences) %>% tidyr::extract(sentence, c("number", "word"), pattern, remove = FALSE) %>% filter(!is.na(number)) #> # A tibble: 22 x 3 #> sentence number word #> <chr> <chr> <chr> #> 1 The rope will bind the seven books at once. seven books #> 2 The two met while playing on the sand. two met #> 3 There are more than two factors here. two factors #> 4 Type out three lists of orders. three lists #> 5 Two plus seven is less than ten. seven is #> 6 Drop the two when you add the figures. two when #> 7 There the flood mark is ten inches. ten inches. #> 8 We are sure that one war is enough. one war #> 9 His shirt was clean but one button was gone. one button #> 10 The fight will end in just six minutes. six minutes. #> # ... with 12 more rows # using str_extract sentences %>% # first get only the sentences containing this pattern str_subset(pattern) %>% # now words that match the pattern str_match(pattern) %>% head(10) #> [,1] [,2] [,3] #> [1,] "seven books" "seven" "books" #> [2,] "two met" "two" "met" #> [3,] "two factors" "two" "factors" #> [4,] "three lists" "three" "lists" #> [5,] "seven is" "seven" "is" #> [6,] "two when" "two" "when" #> [7,] "ten inches." "ten" "inches." #> [8,] "one war" "one" "war" #> [9,] "one button" "one" "button" #> [10,] "six minutes." "six" "minutes." sentences %>% # first get only the sentences containing this pattern str_subset(pattern) %>% # now words that match the pattern str_match_all(pattern) %>% head(10) #> [[1]] #> [,1] [,2] [,3] #> [1,] "seven books" "seven" "books" #> #> [[2]] #> [,1] [,2] [,3] #> [1,] "two met" "two" "met" #> #> [[3]] #> [,1] [,2] [,3] #> [1,] "two factors" "two" "factors" #> #> [[4]] #> [,1] [,2] [,3] #> [1,] "three lists" "three" "lists" #> #> [[5]] #> [,1] [,2] [,3] #> [1,] "seven is" "seven" "is" #> #> [[6]] #> [,1] [,2] [,3] #> [1,] "two when" "two" "when" #> #> [[7]] #> [,1] [,2] [,3] #> [1,] "ten inches." "ten" "inches." #> #> [[8]] #> [,1] [,2] [,3] #> [1,] "one war" "one" "war" #> #> [[9]] #> [,1] [,2] [,3] #> [1,] "one button" "one" "button" #> #> [[10]] #> [,1] [,2] [,3] #> [1,] "six minutes." "six" "minutes."Find all contractions. Separate out the pieces before and after the apostrophe.
pattern <- "\\b([a-zA-Z]+)'([a-zA-Z]+)" tibble(sentence = sentences) %>% tidyr::extract(sentence, c("one", "two"), pattern, remove = FALSE) %>% filter(!is.na(one)) #> # A tibble: 15 x 3 #> sentence one two #> <chr> <chr> <chr> #> 1 It's easy to tell the depth of a well. It s #> 2 The soft cushion broke the man's fall. man s #> 3 Open the crate but don't break the glass. don t #> 4 Add the store's account to the last cent. store s #> 5 The beam dropped down on the workmen's head. workmen s #> 6 Let's all join as we sing the last chorus. Let s #> 7 The copper bowl shone in the sun's rays. sun s #> 8 A child's wit saved the day for us. child s #> 9 A ripe plum is fit for a king's palate. king s #> 10 It's a dense crowd in two distinct ways. It s #> 11 We don't get much money but we have fun. don t #> 12 Ripe pears are fit for a queen's table. queen s #> 13 We don't like to admit our small faults. don t #> 14 Dig deep in the earth for pirate's gold. pirate s #> 15 She saw a cat in the neighbor's house. neighbor s # the str_match way sentences %>% str_subset(pattern) %>% # only consider rows with pattern str_match(pattern) #> [,1] [,2] [,3] #> [1,] "It's" "It" "s" #> [2,] "man's" "man" "s" #> [3,] "don't" "don" "t" #> [4,] "store's" "store" "s" #> [5,] "workmen's" "workmen" "s" #> [6,] "Let's" "Let" "s" #> [7,] "sun's" "sun" "s" #> [8,] "child's" "child" "s" #> [9,] "king's" "king" "s" #> [10,] "It's" "It" "s" #> [11,] "don't" "don" "t" #> [12,] "queen's" "queen" "s" #> [13,] "don't" "don" "t" #> [14,] "pirate's" "pirate" "s" #> [15,] "neighbor's" "neighbor" "s"
Replacing matches
Replacing matches
str_replace() and str_replace_all() allow you to replace matches with new strings.
x <- c("apple", "pear", "banana")
# replace the 1st occurrence of a vowel in x with a -
str_replace(x, "[aeiou]", "-")
#> [1] "-pple" "p-ar" "b-nana"
# replace all occurrences of a vowel in x with a -
str_replace_all(x, "[aeiou]", "-")
#> [1] "-ppl-" "p--r" "b-n-n-"With str_replace_all() you may also supply a named vector to perform multiple replacements.
x <- c("1 house", "2 cars", "3 people")
str_replace_all(x,
c("1" = "one", "2" = "two", "3" = "three"))
#> [1] "one house" "two cars" "three people"We can also use backreferences to do replacements.
# swap the second and third words
sentences %>%
# look for pattern word another_word another_one with
# spaces in between
# without the spaces it swaps the letter in the first word
str_replace("([^ ]+) ([^ ]+) ([^ ]+)", "\\1 \\3 \\2") %>%
head()
#> [1] "The canoe birch slid on the smooth planks."
#> [2] "Glue sheet the to the dark blue background."
#> [3] "It's to easy tell the depth of a well."
#> [4] "These a days chicken leg is a rare dish."
#> [5] "Rice often is served in round bowls."
#> [6] "The of juice lemons makes fine punch."Exercises
Replace all forward slashes in a string with backslashes.
x <- "This is / an arbitrary / contrived example" writeLines(x) #> This is / an arbitrary / contrived example (replace <- str_replace_all(x, "/", "\\\\")) #> [1] "This is \\ an arbitrary \\ contrived example" writeLines(replace) #> This is \ an arbitrary \ contrived exampleImplement a simple version of
str_to_lower()usingreplace_all().x <- "The Quick Brown Fox Jumped Over the Lazy DOG" str_replace_all(x, c("A" = "a", "B" = "b", "C" = "c", "D" = "d", "E" = "e", "F" = "f", "G" = "g", "H" = "h", "I" = "i", "J" = "j", "K" = "k", "L" = "l", "M" = "m", "N" = "n", "O" = "o", "P" ="p", "Q" = "q", "R" = "r", "S" = "s", "T" = "t", "U" = "u", "V" = "v", "W" = "w", "X" = "x", "Y" = "y", "Z" = "z")) #> [1] "the quick brown fox jumped over the lazy dog"Switch the first and last letters in
words. Which of those strings are still words?(replaces <- stringr::words %>% str_replace("^([^ ])([^ ]*)([^ ])$", "\\3\\2\\1")) #> [1] "a" "ebla" "tboua" "ebsoluta" "tccepa" #> [6] "tccouna" "echieva" "scrosa" "tca" "ectiva" #> [11] "lctuaa" "dda" "sddresa" "tdmia" "edvertisa" #> [16] "tffeca" "dffora" "rftea" "nfternooa" "ngaia" #> [21] "tgainsa" "ega" "tgena" "oga" "egrea" #> [26] "ria" "lla" "wlloa" "tlmosa" "glona" #> [31] "ylreada" "tlrigha" "olsa" "hlthouga" "slwaya" #> [36] "america" "tmouna" "dna" "rnothea" "rnswea" #> [41] "yna" "tpara" "tpparena" "rppeaa" "yppla" #> [46] "tppoina" "hpproaca" "eppropriata" "area" "ergua" #> [51] "mra" "drouna" "erranga" "tra" "sa" #> [56] "ksa" "essociata" "essuma" "ta" "dttena" #> [61] "yuthorita" "evailabla" "ewara" "ywaa" "lwfua" #> [66] "yabb" "kacb" "dab" "gab" "ealancb" #> [71] "lalb" "kanb" "rab" "easb" "sasib" #> [76] "eb" "reab" "teab" "yeautb" "eecausb" #> [81] "eecomb" "deb" "eeforb" "negib" "dehinb" #> [86] "eelievb" "tenefib" "tesb" "teb" "netweeb" #> [91] "gib" "lilb" "hirtb" "tib" "klacb" #> [96] "elokb" "dloob" "wlob" "elub" "doarb" #> [101] "toab" "yodb" "koob" "hotb" "rotheb" #> [106] "eottlb" "mottob" "xob" "yob" "kreab" #> [111] "frieb" "trillianb" "grinb" "nritaib" "rrotheb" #> [116] "tudgeb" "duilb" "sub" "susinesb" "yusb" #> [121] "tub" "yub" "yb" "eakc" "lalc" #> [126] "nac" "rac" "darc" "earc" "yarrc" #> [131] "easc" "tac" "hatcc" "eausc" "tenc" #> [136] "eentrc" "nertaic" "rhaic" "nhairmac" "ehancc" #> [141] "ehangc" "phac" "rharactec" "ehargc" "pheac" #> [146] "khecc" "dhilc" "ehoicc" "ehoosc" "thrisC" #> [151] "shristmaC" "hhurcc" "yitc" "mlaic" "slasc" #> [156] "nleac" "rleac" "tlienc" "klocc" "elosc" #> [161] "slosec" "elothc" "bluc" "eoffec" "dolc" #> [166] "eolleaguc" "tollecc" "eollegc" "rolouc" "eomc" #> [171] "tommenc" "tommic" "eommittec" "nommoc" "yommunitc" #> [176] "yompanc" "eomparc" "eompletc" "eomputc" "noncerc" #> [181] "nonditioc" "ronfec" "ronsidec" "tonsulc" "tontacc" #> [186] "eontinuc" "tontracc" "lontroc" "eonversc" "kooc" #> [191] "yopc" "rornec" "torrecc" "tosc" "doulc" #> [196] "louncic" "tounc" "yountrc" "yountc" "eouplc" #> [201] "eoursc" "tourc" "rovec" "ereatc" "srosc" #> [206] "puc" "turrenc" "tuc" "dad" "ranged" #> [211] "eatd" "yad" "dead" "lead" "read" #> [216] "eebatd" "eecidd" "necisiod" "peed" "eefinitd" #> [221] "eegred" "tepartmend" "depend" "eescribd" "nesigd" #> [226] "letaid" "pevelod" "eid" "eifferencd" "tifficuld" #> [231] "rinned" "tirecd" "siscusd" "tistricd" "eividd" #> [236] "od" "roctod" "tocumend" "god" "rood" #> [241] "eoubld" "toubd" "nowd" "wrad" "sresd" #> [246] "krind" "erivd" "prod" "yrd" "eud" #> [251] "gurind" "hace" "yarle" "tase" "yase" #> [256] "tae" "yconome" "educate" "tffece" "gge" #> [261] "tighe" "rithee" "tlece" "clectrie" "nlevee" #> [266] "else" "ymploe" "encourage" "dne" "engine" #> [271] "hnglise" "ynjoe" "hnouge" "rntee" "tnvironmene" #> [276] "lquae" "lspeciae" "europe" "nvee" "gvenine" #> [281] "rvee" "yvere" "evidence" "txace" "example" #> [286] "txcepe" "excuse" "exercise" "txise" "txpece" #> [291] "expense" "experience" "nxplaie" "sxprese" "axtre" #> [296] "eye" "eacf" "tacf" "raif" "lalf" #> [301] "yamilf" "raf" "marf" "tasf" "rathef" #> [306] "ravouf" "deef" "leef" "wef" "dielf" #> [311] "tighf" "eigurf" "eilf" "lilf" "milf" #> [316] "linaf" "einancf" "dinf" "einf" "hinisf" #> [321] "eirf" "tirsf" "hisf" "tif" "eivf" #> [326] "tlaf" "rloof" "ylf" "wollof" "doof" #> [331] "toof" "rof" "eorcf" "torgef" "morf" #> [336] "eortunf" "dorwarf" "rouf" "erancf" "eref" #> [341] "yridaf" "drienf" "mrof" "tronf" "lulf" #> [346] "nuf" "nunctiof" "dunf" "rurthef" "euturf" #> [351] "eamg" "nardeg" "sag" "lenerag" "yermang" #> [356] "teg" "lirg" "eivg" "slasg" "og" #> [361] "dog" "doog" "eoodbyg" "noverg" "drang" #> [366] "trang" "treag" "nreeg" "droung" "proug" #> [371] "wrog" "suesg" "yug" "raih" "falh" #> [376] "lalh" "danh" "ganh" "nappeh" "yapph" #> [381] "darh" "eath" "eavh" "eh" "deah" #> [386] "health" "reah" "tearh" "teah" "yeavh" #> [391] "lelh" "pelh" "eerh" "high" "yistorh" #> [396] "tih" "dolh" "yolidah" "eomh" "tonesh" #> [401] "eoph" "eorsh" "lospitah" "toh" "rouh" #> [406] "eoush" "woh" "roweveh" "oullh" "dundreh" #> [411] "dusbanh" "adei" "ydentifi" "fi" "emagini" #> [416] "tmportani" "emprovi" "ni" "encludi" "encomi" #> [421] "encreasi" "dndeei" "lndividuai" "yndustri" "mnfori" #> [426] "ensidi" "dnsteai" "ensuri" "tnteresi" "onti" #> [431] "entroduci" "tnvesi" "envolvi" "essui" "ti" #> [436] "mtei" "sesuj" "boj" "noij" "eudgj" #> [441] "pumj" "tusj" "peek" "yek" "dik" #> [446] "lilk" "dink" "gink" "nitchek" "knock" #> [451] "wnok" "raboul" "dal" "yadl" "danl" #> [456] "eanguagl" "eargl" "tasl" "eatl" "haugl" #> [461] "wal" "yal" "deal" "nearl" "eeavl" #> [466] "tefl" "gel" "sesl" "tel" "rettel" #> [471] "level" "eil" "eifl" "tighl" "eikl" #> [476] "yikell" "timil" "einl" "kinl" "tisl" #> [481] "nistel" "eittll" "eivl" "doal" "local" #> [486] "kocl" "nondol" "gonl" "kool" "dorl" #> [491] "eosl" "tol" "eovl" "wol" "kucl" #> [496] "huncl" "eachinm" "naim" "rajom" "eakm" #> [501] "nam" "eanagm" "yanm" "karm" "tarkem" #> [506] "yarrm" "hatcm" "rattem" "yam" "eaybm" #> [511] "neam" "geaninm" "eeasurm" "teem" "rembem" #> [516] "nentiom" "eiddlm" "tighm" "eilm" "kilm" #> [521] "nilliom" "dinm" "rinistem" "sinum" "einutm" #> [526] "sism" "ristem" "tomenm" "yondam" "yonem" #> [531] "hontm" "eorm" "gorninm" "tosm" "rothem" #> [536] "notiom" "eovm" "srm" "hucm" "cusim" #> [541] "tusm" "eamn" "nation" "eaturn" "rean" #> [546] "yecessarn" "deen" "reven" "wen" "sewn" #> [551] "texn" "eicn" "tighn" "einn" "on" #> [556] "non" "eonn" "lorman" "hortn" "ton" #> [561] "eotn" "eoticn" "won" "rumben" "sbviouo" #> [566] "nccasioo" "ddo" "fo" "ffo" "rffeo" #> [571] "effico" "nfteo" "ykao" "dlo" "no" #> [576] "enco" "eno" "ynlo" "npeo" "eperato" #> [581] "ypportunito" "epposo" "ro" "rrdeo" "erganizo" #> [586] "lriginao" "rtheo" "etherwiso" "tugho" "tuo" #> [591] "rveo" "nwo" "kacp" "eagp" "tainp" #> [596] "raip" "rapep" "haragrapp" "nardop" "tarenp" #> [601] "karp" "tarp" "rarticulap" "yartp" "sasp" #> [606] "tasp" "yap" "eencp" "nensiop" "eeoplp" #> [611] "rep" "tercenp" "terfecp" "serhapp" "deriop" #> [616] "nersop" "hhotograpp" "kicp" "eicturp" "eiecp" #> [621] "elacp" "nlap" "ylap" "eleasp" "slup" #> [626] "toinp" "eolicp" "yolicp" "colitip" "roop" #> [631] "nositiop" "eositivp" "eossiblp" "tosp" "dounp" #> [636] "rowep" "eractisp" "ereparp" "tresenp" "sresp" #> [641] "eressurp" "eresump" "yrettp" "srevioup" "ericp" #> [646] "trinp" "erivatp" "erobablp" "mroblep" "droceep" #> [651] "srocesp" "eroducp" "troducp" "erogrammp" "trojecp" #> [656] "rropep" "eroposp" "trotecp" "erovidp" "cublip" #> [661] "lulp" "eurposp" "husp" "tup" "yualitq" #> [666] "ruarteq" "nuestioq" "kuicq" "duiq" "tuieq" #> [671] "euitq" "oadir" "lair" "eaisr" "eangr" #> [676] "eatr" "rather" "dear" "yeadr" "lear" #> [681] "eealisr" "yeallr" "neasor" "eeceivr" "tecenr" #> [686] "neckor" "eecognizr" "decommenr" "decorr" "der" #> [691] "eeducr" "refer" "degarr" "negior" "nelatior" #> [696] "remember" "teporr" "tepresenr" "eequirr" "hesearcr" #> [701] "eesourcr" "tespecr" "eesponsiblr" "tesr" "tesulr" #> [706] "neturr" "dir" "tighr" "ginr" "eisr" #> [711] "doar" "eolr" "lolr" "moor" "dounr" #> [716] "eulr" "nur" "eafs" "eals" "eams" #> [721] "yaturdas" "eavs" "yas" "echems" "lchoos" #> [726] "eciencs" "ecors" "dcotlans" "teas" "decons" #> [731] "yecretars" "nectios" "eecurs" "ees" "mees" #> [736] "fels" "lels" "dens" "eenss" "eeparats" #> [741] "serious" "eervs" "eervics" "tes" "eettls" #> [746] "neves" "xes" "lhals" "ehars" "ehs" #> [751] "thees" "ehos" "thoos" "phos" "thors" #> [756] "dhouls" "whos" "thus" "kics" "eids" #> [761] "nigs" "rimilas" "eimpls" "eincs" "gins" #> [766] "eingls" "ris" "ristes" "tis" "eits" #> [771] "eituats" "xis" "eizs" "plees" "tlighs" #> [776] "wlos" "lmals" "emoks" "os" "locias" #> [781] "yociets" "eoms" "nos" "noos" "yorrs" #> [786] "tors" "douns" "houts" "epacs" "kpeas" #> [791] "lpecias" "cpecifis" "dpees" "lpels" "dpens" #> [796] "equars" "ftafs" "etags" "stairs" "dtans" #> [801] "dtandars" "ttars" "etats" "ntatios" "ytas" #> [806] "ptes" "ktics" "ltils" "ptos" "ytors" #> [811] "ttraighs" "ytrategs" "ttrees" "etriks" "gtrons" #> [816] "etructurs" "ttudens" "ytuds" "ftufs" "dtupis" #> [821] "tubjecs" "duccees" "hucs" "nuddes" "tuggess" #> [826] "tuis" "rummes" "nus" "yundas" "yuppls" #> [831] "tuppors" "eupposs" "eurs" "eurpriss" "hwitcs" #> [836] "mystes" "eablt" "eakt" "kalt" "eapt" #> [841] "xat" "aet" "heact" "meat" "eelephont" #> [846] "nelevisiot" "lelt" "net" "dent" "mert" #> [851] "eerriblt" "test" "nhat" "khant" "eht" #> [856] "nhet" "ehert" "eherefort" "yhet" "ghint" #> [861] "khint" "nhirteet" "yhirtt" "shit" "uhot" #> [866] "hhougt" "dhousant" "ehret" "hhrougt" "whrot" #> [871] "yhursdat" "eit" "eimt" "ot" "yodat" #> [876] "rogethet" "womorrot" "tonight" "oot" "pot" #> [881] "lotat" "houct" "dowart" "nowt" "eradt" #> [886] "craffit" "nrait" "transport" "lravet" "treat" #> [891] "eret" "eroublt" "erut" "trust" "yrt" #> [896] "yuesdat" "nurt" "ewelvt" "ywentt" "owt" #> [901] "eypt" "rndeu" "dnderstanu" "nniou" "tniu" #> [906] "enitu" "yniversitu" "snlesu" "lntiu" "pu" #> [911] "npou" "esu" "lsuau" "ealuv" "sariouv" #> [916] "yerv" "oidev" "wiev" "eillagv" "tisiv" #> [921] "eotv" "eagw" "taiw" "kalw" "lalw" #> [926] "tanw" "raw" "marw" "hasw" "eastw" #> [931] "hatcw" "ratew" "yaw" "ew" "reaw" #> [936] "yednesdaw" "eew" "keew" "heigw" "eelcomw" #> [941] "lelw" "tesw" "thaw" "nhew" "eherw" #> [946] "rhethew" "hhicw" "ehilw" "ehitw" "ohw" #> [951] "eholw" "yhw" "eidw" "eifw" "lilw" #> [956] "niw" "dinw" "window" "hisw" "hitw" #> [961] "nithiw" "tithouw" "nomaw" "rondew" "doow" #> [966] "dorw" "korw" "dorlw" "yorrw" "eorsw" #> [971] "hortw" "doulw" "eritw" "gronw" "reay" #> [976] "sey" "yesterday" "tey" "uoy" "gouny" tibble(word = stringr::words) %>% filter(word %in% replaces) %>% head(20) #> # A tibble: 20 x 1 #> word #> <chr> #> 1 a #> 2 america #> 3 area #> 4 dad #> 5 dead #> 6 deal #> 7 dear #> 8 depend #> 9 dog #> 10 educate #> 11 else #> 12 encourage #> 13 engine #> 14 europe #> 15 evidence #> 16 example #> 17 excuse #> 18 exercise #> 19 expense #> 20 experience
Splitting
Splitting
Use str_split() to split a string up into pieces.
# we can split a sentence into words
sentences %>%
head() %>%
str_split(" ")
#> [[1]]
#> [1] "The" "birch" "canoe" "slid" "on" "the" "smooth"
#> [8] "planks."
#>
#> [[2]]
#> [1] "Glue" "the" "sheet" "to" "the"
#> [6] "dark" "blue" "background."
#>
#> [[3]]
#> [1] "It's" "easy" "to" "tell" "the" "depth" "of" "a" "well."
#>
#> [[4]]
#> [1] "These" "days" "a" "chicken" "leg" "is" "a"
#> [8] "rare" "dish."
#>
#> [[5]]
#> [1] "Rice" "is" "often" "served" "in" "round" "bowls."
#>
#> [[6]]
#> [1] "The" "juice" "of" "lemons" "makes" "fine" "punch."This returns a list since the length of each is varying.
To extract a component:
sentences %>%
head() %>%
str_split(" ") %>%
.[[1]]
#> [1] "The" "birch" "canoe" "slid" "on" "the" "smooth"
#> [8] "planks."
"a|b|c|d" %>%
# list returned
str_split("\\|")
#> [[1]]
#> [1] "a" "b" "c" "d"
"a|b|c|d" %>%
# list returned
str_split("\\|") %>%
# get first element
.[[1]]
#> [1] "a" "b" "c" "d"Also like other {stringr} functions there is a simplify = TRUE that may be set.
sentences %>%
head(5) %>%
str_split(" ", simplify = TRUE)
#> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
#> [1,] "The" "birch" "canoe" "slid" "on" "the" "smooth" "planks."
#> [2,] "Glue" "the" "sheet" "to" "the" "dark" "blue" "background."
#> [3,] "It's" "easy" "to" "tell" "the" "depth" "of" "a"
#> [4,] "These" "days" "a" "chicken" "leg" "is" "a" "rare"
#> [5,] "Rice" "is" "often" "served" "in" "round" "bowls." ""
#> [,9]
#> [1,] ""
#> [2,] ""
#> [3,] "well."
#> [4,] "dish."
#> [5,] ""We can also specify we want xx number of pieces only, using n = num_pieces.
sentences %>%
head(5) %>%
str_split(" ", n = 5, simplify = TRUE)
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] "The" "birch" "canoe" "slid" "on the smooth planks."
#> [2,] "Glue" "the" "sheet" "to" "the dark blue background."
#> [3,] "It's" "easy" "to" "tell" "the depth of a well."
#> [4,] "These" "days" "a" "chicken" "leg is a rare dish."
#> [5,] "Rice" "is" "often" "served" "in round bowls."Notice that the remaining part of the string all goes into the last piece!
fields <- c("Name: Hadley", "Country: NZ", "Age: 35")
fields %>%
str_split(": ", n = 2, simplify = TRUE)
#> [,1] [,2]
#> [1,] "Name" "Hadley"
#> [2,] "Country" "NZ"
#> [3,] "Age" "35"So far we split on a pattern. We may also split by:
- character
- line
- sentence
- word
boundary() - The function
boundary()has different types - e.gline_break,wordetc.
x <- "This is a sentence. This is another sentence."
str_view_all(x, boundary("word"))
str_split(x, " ")[[1]]
#> [1] "This" "is" "a" "sentence." "" "This"
#> [7] "is" "another" "sentence."
str_split(x, boundary("word"))[[1]]
#> [1] "This" "is" "a" "sentence" "This" "is" "another"
#> [8] "sentence"Exercises
Split up a string like
"apples, pears, and bananas"into individual components.test_str <- "apples, pears, and bananas" str_split(test_str, ", (and)?", n=3)[[1]] #> [1] "apples" "pears" " bananas"Why is it better to split up by
boundary("word")than" "?x <- "This is a sentence, this is another sentence." str_view_all(x, boundary("word"))str_split(x, " ")[[1]] #> [1] "This" "is" "a" "sentence," "this" "is" #> [7] "another" "sentence." str_split(x, boundary("word"))[[1]] #> [1] "This" "is" "a" "sentence" "this" "is" "another" #> [8] "sentence"As we saw in the example splitting by
" "can lead to punctuation being added to a split word. Here:sentence.andsentence,.With using
boundary(word)it ignores the puntuation resulting in pure words being picked up.What does splitting with an empty string (
"") do? Experiment, and then read the documentation.x <- "This is a sentence, this is another sentence." str_split(x, "")[[1]] #> [1] "T" "h" "i" "s" " " "i" "s" " " "a" " " "s" "e" "n" "t" "e" "n" "c" "e" "," #> [20] " " "t" "h" "i" "s" " " "i" "s" " " "a" "n" "o" "t" "h" "e" "r" " " "s" "e" #> [39] "n" "t" "e" "n" "c" "e" "." str_split(x, boundary("character"))[[1]] #> [1] "T" "h" "i" "s" " " "i" "s" " " "a" " " "s" "e" "n" "t" "e" "n" "c" "e" "," #> [20] " " "t" "h" "i" "s" " " "i" "s" " " "a" "n" "o" "t" "h" "e" "r" " " "s" "e" #> [39] "n" "t" "e" "n" "c" "e" "."It splits on each character. It is equivalent to splitting on
boundary("character")
Find matches
str_locate() and str_locate_all() give you the starting and ending positions of each match. Use str_locate() to find the matching pattern, str_sub() to extract.
Other Patterns
Other Patterns
When you use a pattern that’s a string, it’s automatically wrapped into a call to regex()
# regular usage
str_view(fruit, "nana")
# behind the scenes - note the Same result
str_view(fruit, regex("nana"))Other arguments ofregex() to control details of the match are:
ignore_case = TRUEallows characters to match either their uppercase or lowercase versions.
bananas <- c("banana", "Banana", "BANANA")
# match case sensitive value
str_view(bananas, "banana")
# match case insensitive value
str_view(bananas, regex("banana", ignore_case = TRUE))multiline = TRUEallows^and$to match the start and end of each line rather than the start and end of the complete string.
x <- "Line 1\nLine 2\nLine 3"
# extract where it starts with Line - only 1st caught
str_extract_all(x, "^Line")[[1]]
#> [1] "Line"
# using regex multiline
str_extract_all(x, regex("^Line", multiline = TRUE))[[1]]
#> [1] "Line" "Line" "Line"comments = TRUEallows the use of comments and white space to make complex regular expressions more understandable. Spaces are ignored, as is everything after#. To match a literal space, escape it:"\\ ".
phone <- regex("
\\(? # optional opening parens
(\\d{3}) # area code
[)\\ -]? # optional closing parens, dash or space
(\\d{3}) # another three numbers
[\\ -]? # optional space or dash
(\\d{3}) # three more numbers
", comments = TRUE)
str_match(c("514-791-8141",
"(011)763-813",
"200 900-453"), phone)
#> [,1] [,2] [,3] [,4]
#> [1,] "514-791-814" "514" "791" "814"
#> [2,] "(011)763-813" "011" "763" "813"
#> [3,] "200 900-453" "200" "900" "453"dotall = TRUEallows.to match everything, including\n.
Other functions
fixed(): matches exactly the specified sequence of bytes. It ignores all special regular expressions and can be much faster than regular expressions.microbenchmark::microbenchmark( fixed = str_detect(sentences, fixed("the")), regex = str_detect(sentences, "the"), times = 20 ) #> Unit: microseconds #> expr min lq mean median uq max neval #> fixed 106.7 111.9 134.565 115.60 130.35 300.7 20 #> regex 291.0 298.5 341.850 303.95 326.80 605.9 20Using
fixed()with non-English data is sometimes problematic because there are multiple ways of representing the same character. Here are two ways to define “á”:a1 <- "\u00e1" a2 <- "a\u0301" c(a1, a2) #> [1] "á" "a´" a1 == a2 #> [1] FALSEWhile they render the same they’re defined differently, so
fixed()doesn’t find a match. Instead, you can usecoll()to respect human character rules.str_detect(a1, fixed(a2)) #> [1] FALSE str_detect(a1, coll(a2)) #> [1] TRUEcoll(): compare strings using standard collation rules - useful for doing case insensitive matching.coll()takes alocaleparameter that controls which rules are used for comparing characters. Note: Changing locale, does not work as in the bookcoll()is slow.# That means you also need to be aware of the difference # when doing case insensitive matches: i <- c("I", "İ", "i", "ı") i #> [1] "I" "I" "i" "i" str_subset(i, coll("i", ignore_case = TRUE)) #> [1] "I" "I" "i" "i" str_subset(i, coll("i", ignore_case = TRUE, locale = "tr")) #> [1] "i" "i"Both
fixed()andregex()haveignore_casearguments, but they do not allow you to pick the locale: they always use the default locale.stringi::stri_locale_info() #> $Language #> [1] "en" #> #> $Country #> [1] "ZA" #> #> $Variant #> [1] "" #> #> $Name #> [1] "en_ZA"You can use
boundary()to match boundaries with other functions besidesstr_split().x <- "This is a sentence." str_view_all(x, boundary("word"))str_extract_all(x, boundary("word")) #> [[1]] #> [1] "This" "is" "a" "sentence"
Exercises
How would you find all strings containing
\withregex()vs. withfixed()?(backslash <- "This string contains the \\ char and we want to find it.") #> [1] "This string contains the \\ char and we\nwant to find it." writeLines(backslash) #> This string contains the \ char and we #> want to find it. str_view(backslash, regex("\\\\"))str_view(backslash, fixed("\\"))What are the five most common words in
sentences?tibble(word = unlist(str_split(sentences, boundary("word")))) %>% mutate(word = str_to_lower(word)) %>% count(word, sort = TRUE) #> # A tibble: 1,904 x 2 #> word n #> <chr> <int> #> 1 the 751 #> 2 a 202 #> 3 of 132 #> 4 to 123 #> 5 and 118 #> 6 in 87 #> 7 is 81 #> 8 was 66 #> 9 on 60 #> 10 with 51 #> # ... with 1,894 more rows
Other uses of regex
Other uses of regex
Base R
apropos()searches all objects available from the global environment. Useful if you can’t quite remember the name of the function.apropos("replace") #> [1] "%+replace%" "replace" "replace" "replace_na" #> [5] "replaces" "setReplaceMethod" "str_replace" "str_replace_all" #> [9] "str_replace_na" "theme_replace"Base R
dir()lists all the files in a directory. Thepatternargument takes a regular expression and only returns file names that match the pattern.head(dir("analysis", pattern = "\\.Rmd$")) # match all Rmd files #> [1] "about.Rmd" "ch1_ggplot.Rmd" #> [3] "ch10_relations_dplyr.Rmd" "ch11_strings.Rmd" #> [5] "ch12_forcats.Rmd" "ch13_datetimes.Rmd"You may also use “globs” like
*.Rmd, by converting them to regular expressions withglob2rx():head(dir("analysis", pattern = glob2rx("*.Rmd"))) # match all Rmd files #> [1] "about.Rmd" "ch1_ggplot.Rmd" #> [3] "ch10_relations_dplyr.Rmd" "ch11_strings.Rmd" #> [5] "ch12_forcats.Rmd" "ch13_datetimes.Rmd"
stringi
stringr is built on top of the stringi package, which is more comprehensive than stringr.
Exercises
Find the stringi functions that:
Count the number of words.
s <- 'Lorem ipsum dolor sit amet, consectetur adipisicing elit.' stringi::stri_count(s, regex="\\w+") #> [1] 8Find duplicated strings.
stringi::stri_duplicated(c('a', 'b', 'a', NA, 'a', NA)) #> [1] FALSE FALSE TRUE FALSE TRUE TRUEGenerate random text.
cat(sapply( stringi::stri_wrap(stringi::stri_rand_lipsum(10), 80, simplify=FALSE), stringi::stri_flatten, collapse='\n'), sep='\n\n') #> Lorem ipsum dolor sit amet, et, neque mollis amet quam vulputate, quam vitae #> sit massa. Mauris ac. Libero ornare vitae facilisis sed. Nullam tristique nam, #> eu eros placerat, lorem, duis porttitor. Placerat sed lacus leo et, pretium #> eget, aptent. Urna mollis nibh augue porta vel quis commodo suspendisse tortor #> aliquam. Scelerisque porta, ante sed et cum conubia hac? Eu finibus, sapien #> senectus lectus mattis. Ut mus aptent, nec litora porta lobortis ultricies #> rutrum? Semper consectetur nascetur litora mauris curabitur nec turpis taciti. #> Facilisi quam nec velit. Ut augue mauris sed sed et justo scelerisque porttitor #> tincidunt. Imperdiet ipsum sed senectus in vitae a turpis aliquam dignissim. #> Fermentum lacus et eleifend gravida in mauris. Et litora ut sodales vel vitae #> efficitur congue in tellus nunc. At, sagittis scelerisque pharetra nullam #> facilisis purus mattis nec feugiat nisl nec et habitant elementum natoque eget. #> Et at arcu habitasse ac pulvinar suspendisse aptent sed. #> #> Varius penatibus. Facilisis leo fusce. Nec, aliquet lobortis et magnis nulla #> vestibulum. Non nullam pretium quam condimentum diam arcu tellus, ultrices #> nibh nibh praesent. Non etiam tempor, aliquam egestas. Nibh mauris massa, eget #> consequat tortor, aenean natoque orci in dapibus curabitur. Nec ut mauris erat #> conubia aliquam congue. Nunc, ullamcorper in pellentesque venenatis convallis #> montes rhoncus. Quis justo sapien tempor nec. Sed, rutrum parturient, vestibulum #> nulla dolor lacus ipsum. #> #> Ultrices, pellentesque senectus luctus augue netus! In nascetur volutpat nec #> urna. Per efficitur nec etiam in ut velit, non. Dignissim at ante curabitur ut, #> nostra, ipsum luctus, efficitur felis. Et ultricies maecenas ultrices, sit a #> enim ut lobortis ut ac nam. Amet cum amet. Pellentesque donec facilisi vehicula #> eget eget donec tellus velit. Sollicitudin et in sed dapibus. Sit faucibus. #> At aenean ipsum cubilia phasellus. Mauris mollis placerat justo sed sed ut et. #> Malesuada integer ligula turpis in donec in aliquam ac sit. Maecenas class massa #> ligula. #> #> Cursus aliquam quis aptent nunc iaculis mollis odio a tellus! Quisque egestas #> non donec lacus sapien cubilia tincidunt. Ac habitant turpis risus. Egestas #> praesent fermentum dictum iaculis mauris sit purus auctor. Faucibus elementum #> odio egestas felis ut porta ut. Congue dictumst cubilia sed ut tempor sapien #> condimentum consequat. Et pharetra libero in torquent. Vulputate sapien inceptos #> cursus congue aenean class, per augue. #> #> Netus risus eget, efficitur egestas et. Mattis tortor amet quis pharetra luctus. #> Sed nulla velit, nullam et donec ante. Ac mauris in nunc a quam class, in #> egestas. Et himenaeos, penatibus proin auctor, tortor. Velit ipsum feugiat eget #> aliquam auctor blandit luctus. Fusce, semper non tempor sed dignissim fusce #> tempor habitant maecenas. Lacinia metus pharetra dictumst mauris elementum mi. #> Parturient parturient semper dapibus egestas. Lobortis duis rutrum quisque sed #> venenatis pharetra ac. Senectus ac. Turpis curae est sem elementum. Mi feugiat #> aliquam gravida nunc. #> #> Ligula congue libero laoreet consequat ipsum dapibus nec efficitur. Purus #> vel diam ullamcorper et litora felis eu vestibulum. Montes in fringilla netus #> faucibus vel ipsum. Senectus sed, vivamus felis nec consectetur sed suscipit #> aliquet habitasse tempus. Nec ullamcorper, tincidunt efficitur ultrices #> vulputate. Ridiculus magna sociosqu ut lectus enim, placerat. Nunc sed sapien #> consectetur sed penatibus odio faucibus in lectus. Dapibus, suspendisse enim #> senectus tellus tempus eget hac, elementum lacus accumsan. Praesent justo #> gravida, imperdiet dolor elit aliquam metus mi. #> #> Hendrerit vulputate magna, quis, nisl vitae magna. Gravida interdum, ante amet #> posuere et et ac tincidunt. Ut scelerisque, non. Sed sed erat bibendum, sapien, #> sapien inceptos torquent ipsum varius. Ut at eros et, in pellentesque nulla. #> Convallis tristique pretium mollis, leo vitae augue. Et suspendisse varius #> elementum lacus nam ac viverra! Mollis dictumst velit ligula sed primis nibh. #> Lobortis, imperdiet! Euismod proin ullamcorper urna leo donec in diam rutrum! #> Pulvinar ut, quisque ac suspendisse ante ornare, eget natoque. Non euismod #> sed dui facilisis nisi. Interdum est potenti vestibulum dui adipiscing aptent #> conubia nec mollis. #> #> Molestie, aenean habitant nibh ac mauris, tempor et in at diam! A nullam commodo #> cubilia. Consectetur nec ligula cursus ultricies dolor, sed at mollis dis et. #> Et auctor nunc ac orci. Sit elit, malesuada facilisi curae nec dolor. Velit #> penatibus sem sed et et. Tristique accumsan in quam non platea, dolor erat #> nec. Quis vestibulum ut habitant consectetur tellus. In ante diam eu vitae #> ac inceptos et nibh sociosqu sed nec fringilla eu tincidunt vitae, tristique #> gravida nostra sit. #> #> Ut in mauris sagittis maecenas nec. Blandit, sodales et nostra pellentesque #> senectus sed, quam velit sed! A lorem quis id odio vel. Venenatis ultricies duis #> libero sollicitudin lorem nec erat facilisi quis. Mus, dapibus eu molestie proin #> amet. Cras netus lorem ac, in magna, tempor. Non metus a a quis cum suspendisse #> purus, blandit nullam vehicula, pharetra id purus. Tempor lacinia, iaculis, #> orci. Ligula quisque, in augue tincidunt adipiscing sapien. #> #> Mi feugiat amet, rutrum laoreet sed cum. Vel amet, est proin augue in #> condimentum eu lobortis, phasellus ut. Aliquam nulla massa ut ut lectus orci, #> cras mi. Laoreet vel accumsan eros, eu finibus dignissim platea, varius potenti. #> Id ut odio, inceptos sed justo at eget sed sed. Odio non egestas conubia #> non non, praesent. Tellus penatibus a. Est proin, mi montes class tincidunt #> suspendisse libero sed. Ac et ut leo interdum. Tellus sit iaculis lacinia. Metus #> venenatis erat vitae ut? Ipsum fusce nisl, venenatis. Mauris a integer eget, #> in sed vel dictumst mi lacus vivamus. Nec finibus augue sem risus sociis curae #> tempor phasellus et. Arcu, tincidunt malesuada nisl ac, tortor. cat(stringi::stri_rand_lipsum(10), sep='\n\n') #> Lorem ipsum dolor sit amet, donec potenti elit sed sed faucibus sit ultricies. Maximus blandit diam amet laoreet pharetra, posuere aptent quis auctor massa orci. Dapibus sollicitudin eget dictumst eu at urna. Ante in magnis morbi varius lacus elit nec at. Suspendisse lectus aliquam feugiat augue sapien nisi nec nostra. Ut vehicula ligula in leo sodales. Eu felis turpis taciti nulla cras sed. Torquent metus ac lacus dignissim quis auctor sed tristique purus dictumst. #> #> Senectus, platea vitae. Finibus vitae nisl. Ante varius habitasse ac donec sit sit vestibulum, nam dui risus dictum turpis, ut. Euismod ullamcorper nibh risus vitae dui, sapien senectus. Vel leo aenean vitae vivamus nec tortor sed sed mattis cum quis pretium sed. Viverra, vel suscipit pellentesque nostra ante, praesent eu. Hac pretium non sed tincidunt. Mi sapien nec et amet sed sed sit, ac eu habitant in. Ultricies blandit nascetur in leo nam ipsum tempor duis parturient, sed sed. Semper interdum habitasse ultricies vestibulum lacus nulla. Arcu faucibus vestibulum amet. In sociis primis etiam sit ante, habitasse. #> #> Suspendisse enim himenaeos amet erat accumsan. Turpis nunc ac, turpis, commodo in urna. Vestibulum eget iaculis nam malesuada eros turpis dolor potenti. Nisl nisi sit ornare nullam porttitor risus aenean lacinia finibus turpis. Risus eu suspendisse a nam. Nostra turpis odio et cursus venenatis dolor lobortis! Nam felis mi sed et non vehicula maecenas. Inceptos per id et scelerisque id sapien pellentesque sed. A sed, sem eu mattis venenatis sed. #> #> Suspendisse sed ante sed metus fames maximus egestas non non. Ut aliquam ut tincidunt adipiscing aliquam augue fermentum finibus aliquam. Eros eleifend integer praesent pharetra condimentum rutrum non mauris donec congue. Imperdiet neque sed eu, ut sed sed mi libero cum. Rhoncus aliquam auctor himenaeos quam urna ipsum maecenas sed. Tortor leo orci conubia sapien eu porta. Aliquam torquent vitae platea mus vitae. Non id sit in et nibh, facilisis eget facilisis quis aptent risus. Vitae potenti, curabitur pulvinar parturient netus amet lacinia in dictum volutpat, pharetra sodales vestibulum eu. Sodales lorem, aenean, sed facilisis. Vestibulum ultricies, hendrerit efficitur viverra. Ullamcorper sapien id libero et non. Pulvinar felis enim, hendrerit ad ante integer purus purus, amet at ante suspendisse interdum. Cras gravida enim vestibulum eros imperdiet sed. Et sapien interdum, nec mi elementum donec torquent. Nec mauris cum et ut, enim faucibus nunc, et, id magnis blandit. Vitae in dis sit class eu et gravida viverra suspendisse? Ligula aenean magna cum augue eu vel, sem. #> #> Facilisis aliquam est tellus ridiculus dolor odio id. Nec aliquam quam per felis. Viverra pharetra et amet sapien ut ad lacinia. Sapien tincidunt feugiat gravida, quisque blandit taciti aenean donec nunc sem sagittis. Primis, himenaeos tempus mauris dolor. Velit diam tortor. Mattis felis pulvinar vitae conubia ac ex dolor mattis magnis. Vel magna, amet malesuada vivamus eget montes lorem. Mauris natoque elit fermentum fermentum accumsan, malesuada aliquam. Sollicitudin donec felis purus, rutrum et vivamus imperdiet dapibus, nascetur, dignissim. Ut donec luctus. Semper nunc dui, vehicula vestibulum sed. Dapibus eu enim commodo cursus sapien, imperdiet ut nunc. Eleifend quam tempus lobortis curabitur enim risus duis senectus. #> #> Ac velit est amet sociis, consectetur ac porttitor neque. Mauris ut vitae semper accumsan primis vehicula. Mauris proin nulla accumsan erat nulla, luctus, vel sed. Mus molestie, bibendum accumsan volutpat nibh, mauris metus erat nec, tincidunt. Curabitur ac finibus turpis nibh potenti nisl eget. Ultricies augue et maximus ac nec maecenas, velit tempus ac et etiam. Ultricies aliquam vehicula sed. Condimentum tincidunt ligula inceptos risus fringilla arcu nascetur aptent eros. Per sodales tortor faucibus sagittis velit, eros finibus et lacus cras dictum vulputate. Sociosqu in sem in, sed fermentum nulla volutpat sed, ut magna. Sem, a fermentum imperdiet purus arcu mollis felis id in donec. #> #> Praesent odio proin accumsan habitasse vulputate eros. Inceptos velit lectus diam justo donec sem nostra placerat a pretium dolor. Dis mollis suspendisse senectus ex, nam varius faucibus magna ipsum eu. Ex sed leo risus ligula maecenas. Integer risus et aliquam ac sociosqu magnis lorem id blandit! Natoque varius quam sit arcu sociis. Sodales ac justo litora quis sapien mollis finibus et non himenaeos non. Ex, tempor sagittis varius tempus scelerisque, eleifend ligula. #> #> Efficitur curabitur nam primis sed ac ligula ut molestie donec. Nostra nunc lectus tempor sed, nunc, euismod mi eu dapibus! Vulputate nisi eros netus eu, ipsum, adipiscing et curabitur id, eget. Iaculis, libero, sem donec sit iaculis. Etiam, potenti dictum, non amet, ut. At quam amet mauris ad laoreet! Lobortis sed ut eget, dignissim dictum, netus vitae eros in non, class. Sem vitae rhoncus ut quis, class, quisque. Sit tincidunt, quam tincidunt diam est pulvinar ex, convallis curae. Donec sed venenatis, velit maecenas posuere in donec mi potenti. Enim nisi cursus porta donec. #> #> Eget vestibulum venenatis vivamus ligula vitae. Urna cursus potenti vestibulum. Ut tempus ridiculus interdum egestas, massa inceptos per. Eget augue laoreet at, ad. Ante nisl quis fames, dolor efficitur sed lacus tristique taciti egestas quam. Dolor lacinia sit vel hendrerit bibendum iaculis eleifend vehicula. Class mauris porttitor bibendum per phasellus purus imperdiet vulputate. Lectus bibendum. At lacus senectus condimentum ac et tempor blandit suscipit velit. Suscipit pellentesque nam, et, in aliquam rutrum. Bibendum donec mattis etiam amet tincidunt massa vehicula. Penatibus tellus natoque. Purus ridiculus justo, aliquet ultricies a mauris. Turpis volutpat netus mauris. #> #> Neque dis natoque in elementum sed nisi. Porttitor, et dui varius, sed sagittis nam et neque. Enim eu, nunc finibus nisi id maecenas interdum magna augue ut non. Ac egestas fringilla orci et. Dui mauris sed turpis ac litora purus felis et. Vestibulum faucibus, nascetur in sed purus, egestas malesuada aliquam non ac. Cras metus bibendum non mi, sed metus, adipiscing. Ante suspendisse non a ante duis praesent neque non, facilisis vitae nibh. Suscipit placerat eros velit nunc velit volutpat, pretium eleifend vel duis morbi. Eu pellentesque, porttitor purus condimentum, tincidunt porttitor. In eros orci elementum ligula nisl fermentum nam et leo.
How do you control the language that
stri_sort()uses for sorting?stringi::stri_sort(c('hladny', 'chladny'), locale='pl_PL') #> [1] "chladny" "hladny" stringi::stri_sort(c('hladny', 'chladny'), locale='sk_SK') #> [1] "hladny" "chladny"
sessionInfo()
#> R version 3.6.3 (2020-02-29)
#> Platform: x86_64-w64-mingw32/x64 (64-bit)
#> Running under: Windows 10 x64 (build 19042)
#>
#> Matrix products: default
#>
#> locale:
#> [1] LC_COLLATE=English_South Africa.1252 LC_CTYPE=English_South Africa.1252
#> [3] LC_MONETARY=English_South Africa.1252 LC_NUMERIC=C
#> [5] LC_TIME=English_South Africa.1252
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] magrittr_1.5 flair_0.0.2 forcats_0.5.0 stringr_1.4.0
#> [5] dplyr_1.0.2 purrr_0.3.4 readr_1.4.0 tidyr_1.1.2
#> [9] tibble_3.0.3 ggplot2_3.3.2 tidyverse_1.3.0 workflowr_1.6.2
#>
#> loaded via a namespace (and not attached):
#> [1] tidyselect_1.1.0 xfun_0.13 haven_2.3.1
#> [4] colorspace_1.4-1 vctrs_0.3.2 generics_0.0.2
#> [7] htmltools_0.5.0 emo_0.0.0.9000 yaml_2.2.1
#> [10] utf8_1.1.4 rlang_0.4.8 later_1.0.0
#> [13] pillar_1.4.6 withr_2.2.0 glue_1.4.2
#> [16] DBI_1.1.0 dbplyr_2.0.0 modelr_0.1.8
#> [19] readxl_1.3.1 lifecycle_0.2.0 munsell_0.5.0
#> [22] gtable_0.3.0 cellranger_1.1.0 rvest_0.3.6
#> [25] htmlwidgets_1.5.1 evaluate_0.14 knitr_1.28
#> [28] ps_1.3.2 httpuv_1.5.2 fansi_0.4.1
#> [31] broom_0.7.2 Rcpp_1.0.4.6 promises_1.1.0
#> [34] backports_1.1.6 scales_1.1.0 jsonlite_1.7.1
#> [37] fs_1.5.0 microbenchmark_1.4-7 hms_0.5.3
#> [40] digest_0.6.27 stringi_1.5.3 rprojroot_1.3-2
#> [43] grid_3.6.3 cli_2.1.0 tools_3.6.3
#> [46] crayon_1.3.4 whisker_0.4 pkgconfig_2.0.3
#> [49] ellipsis_0.3.1 xml2_1.3.2 reprex_0.3.0
#> [52] lubridate_1.7.9 assertthat_0.2.1 rmarkdown_2.4
#> [55] httr_1.4.2 rstudioapi_0.11 R6_2.4.1
#> [58] git2r_0.26.1 compiler_3.6.3